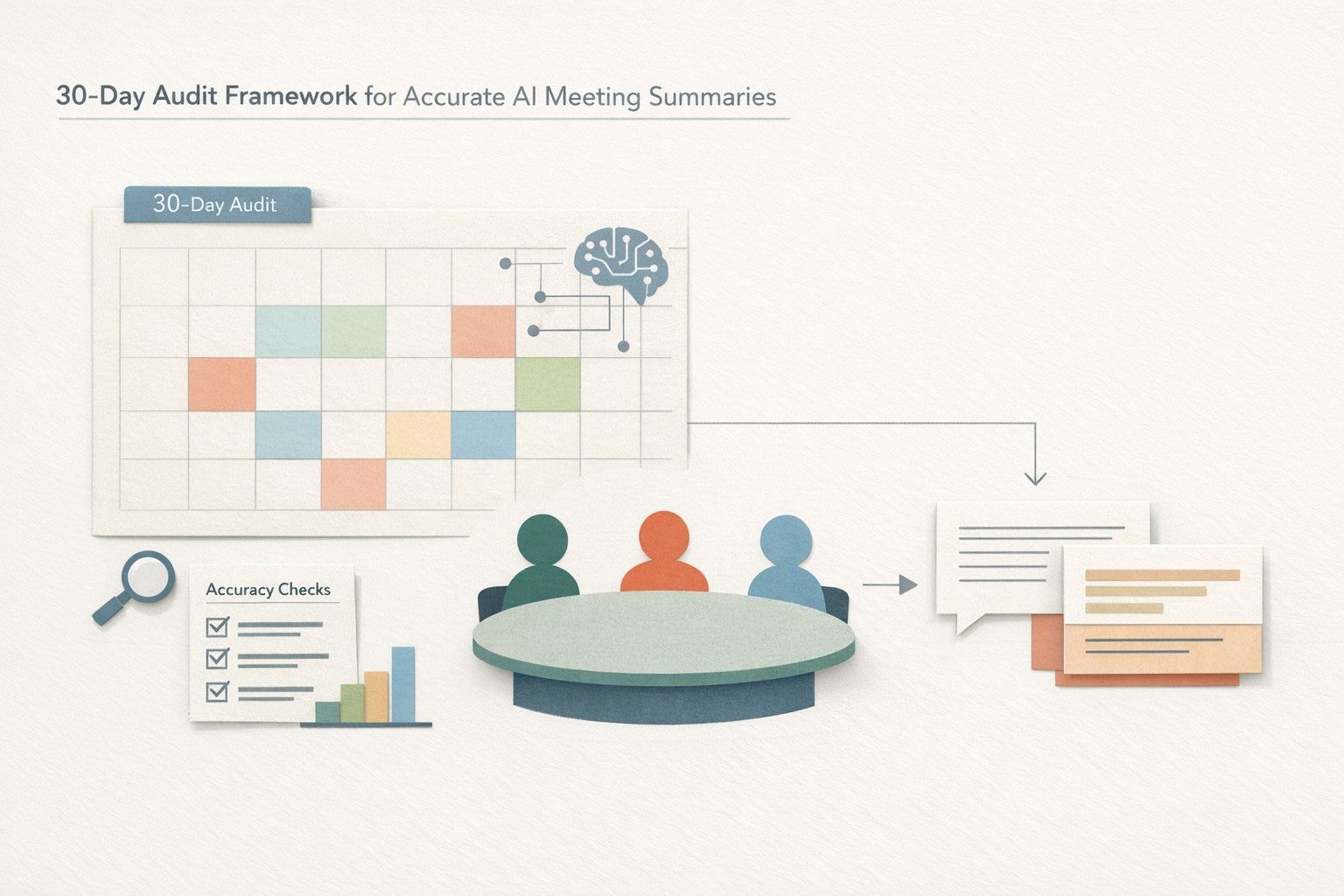
A 30-Day Audit Framework for Accurate AI Meeting Summaries
A practical 30-day audit plan to measure and improve AI meeting summary accuracy with ground truth, taxonomy, and owners.
By Casey
Calibrating AI meeting summary accuracy with a 30-day audit
AI meeting summaries are only as valuable as the decisions they preserve. When a summary misses a constraint, flips a commitment, or attributes a decision to the wrong person, the downstream cost shows up in churned deals, misaligned execution, and unnecessary follow-up meetings. A practical way to prevent that drift is to audit accuracy the way engineering teams audit reliability: with ground-truth samples, a clear error taxonomy, and ownership rules that make fixes stick.
This framework is designed for a 30-day cycle. It works for individuals piloting an AI notetaker and for teams deploying it at scale across sales, customer success, product, and internal ops. Tools like Fathom make it easy to capture transcripts, summaries, action items, and searchable context—an audit turns that output into a measurable quality system.
Define “accurate” before you measure it
Most teams jump straight to scoring summaries without deciding what “accurate” means. Start with three tiers of output, because each has different failure modes:
- Decisions: what was agreed, by whom, and under what conditions.
- Action items: who owns what, by when, and with what definition of done.
- Context: key constraints, objections, assumptions, risks, and rationale.
Then set an explicit audit goal. Examples: “Reduce decision misstatements to near-zero,” “Make action-item ownership unambiguous,” or “Improve capture of objections in sales calls.” The goal matters because your sampling and taxonomy should bias toward your highest-risk failure types.
Set up ground-truth samples that don’t lie
AI output is easy to grade poorly if the grader doesn’t share a single reference point. Ground truth should be consistent, reviewable, and representative.
1) Choose a sampling strategy for 30 days
- Week 1 baseline: sample broadly across meeting types (sales, onboarding, 1:1s, standups, roadmap reviews).
- Weeks 2–3 targeted: oversample the meetings that create the most costly misunderstandings (pricing calls, renewal conversations, incident reviews, executive decisions).
- Week 4 regression check: resample the same categories as Week 1 to see whether changes actually improved accuracy.
Keep the initial sample small enough to complete—think 20–40 meetings over the month for a team rollout, fewer for a pilot—while ensuring each critical meeting type appears multiple times.
2) Build ground truth with a repeatable method
Pick one of these approaches and standardize it across reviewers:
- Dual-reviewer notes: two humans independently write a short “gold summary,” then reconcile differences.
- Transcript-anchored checklist: reviewers must cite exact transcript timestamps for each decision/action item in the gold summary.
- Owner confirmation: the meeting owner signs off on the gold summary within 24–48 hours, while the context is still fresh.
Transcript anchoring is especially effective because it turns “I think it was implied” into “it was said here,” which reduces debates and makes errors easier to categorize and fix.
Create an error taxonomy you can act on
A useful taxonomy does two things: it makes scoring consistent, and it points directly to corrective actions (prompting, vocabulary, workflow, training, or product changes). Use a small set of categories with clear examples.
Core error categories
- Omission: a key decision, action, constraint, or objection is missing.
- Commission: the summary invents or asserts something not supported by the transcript.
- Misattribution: wrong speaker, wrong owner, or wrong team is credited with a statement or commitment.
- Wrong specificity: accurate direction but incorrect details (dates, amounts, feature names, scope).
- Ambiguity: action items lack owner, deadline, or definition of done; decisions lack conditions.
- Priority distortion: minor topics are elevated; critical topics are buried.
Include severity levels so the audit highlights business risk rather than cosmetic style preferences:
- Severity 1 (Critical): would cause a wrong decision, customer promise, compliance issue, or missed deadline.
- Severity 2 (Material): would cause rework, confusion, or follow-up overhead.
- Severity 3 (Minor): wording, formatting, or low-impact gaps.
Score meetings consistently with a simple rubric
Use a scorecard that balances speed and rigor. For each sampled meeting, reviewers record:
- Decision accuracy: count of correct decisions captured / total decisions in ground truth.
- Action-item accuracy: correct owner + correct task + correct due date (or “no due date stated”).
- Critical error count: number of Severity 1 issues by taxonomy category.
- Confidence flags: where the transcript is unclear, jargon-heavy, or multi-threaded.
Two practical scoring tips:
- Prefer counts over vibes: “2 decisions missed, 1 misattributed action item” is more actionable than “summary felt off.”
- Track error rate per hour of meeting time: it normalizes across 15-minute syncs and 60-minute reviews.
Assign ownership rules so fixes happen
An audit without ownership becomes a recurring complaint. Define who owns which class of fix, and how quickly it must be addressed.
Ownership model
- Meeting owner: responsible for confirming decisions and action items within an agreed window (for example, 24 hours).
- Ops owner (RevOps, CS Ops, or EngOps): owns the audit process, dashboards, and sampling.
- Tool admin: manages configuration (templates, integrations, data retention, permissions) and publishes best practices.
- Functional leads: define what “good” looks like in their meeting types (sales call vs. incident review).
If your organization already uses a RACI approach for specs and edge cases, reuse that structure for summary accuracy so responsibilities are explicit rather than implied.
Turn error patterns into improvements in week 2 and week 3
The goal is not a perfect score; it’s controlled improvement on the errors that create real cost.
Common interventions mapped to taxonomy
- Omissions: add a “Decisions / Action items / Risks” structure; enforce a review step for high-stakes meetings.
- Misattribution: standardize participant names and roles; ensure calendars and meeting titles are clean.
- Wrong specificity: add a custom vocabulary for product terms, customer names, acronyms, and pricing packages.
- Ambiguity: require owner + due date fields in the action-item format; push tasks into the system of record.

Integrations matter here: when summaries and tasks reliably land in Slack, Salesforce, HubSpot, Asana, or Notion, the review loop becomes part of daily work rather than a separate quality exercise.
Report results in a way leadership can use
At the end of 30 days, publish a one-page readout:
- Baseline vs. end-of-month: decision capture rate, action-item correctness, and Severity 1 error trend.
- Top 3 error categories: what they are, where they occur, and what changed.
- Meeting types at risk: categories that need tighter review or configuration.
- Policy updates: any new rules for meeting owners, naming conventions, or review timing.
Keep the language operational. The audit should read like a reliability report, not a vendor evaluation. If you want a durable workflow, treat the notetaker as infrastructure: configure it once, measure it continuously, and assign ownership when it fails.
Two practical ways to make the audit easier next month
- Centralize “truth” for terminology and commitments: when teams don’t share definitions, the summary can’t either. The same discipline used to create a single source of truth for specs applies to meetings.
- Deduplicate feedback and follow-ups: if post-meeting notes generate repeated feature requests or recurring issues, use a structured dedup process so the audit doesn’t just document the same problems in new wording. A useful reference is this piece on feedback deduplication.