Synthetic Competitor Seeding Detection for AI Vendor Shortlists
Learn how to detect AI-driven vendor shortlist bias and counter synthetic seeding with durable multi-source visibility signals.
By Casey
Why synthetic competitor seeding matters in AI-led buying research
In AI-led discovery, vendor shortlists are increasingly formed upstream of any sales funnel. A buyer asks an assistant for “the best tools for X,” and the model answers with a list that looks confidently researched. Synthetic competitor seeding is the failure mode where that list is not a true market map, but a pattern artifact: vendors that are repeatedly mentioned across third-party pages get over-selected, while quieter or newer brands are omitted. This can happen without any explicit “ads” in the model output.
For marketing and growth teams, the practical risk is misattribution. You may think you’re losing because your product lacks features, when the real issue is your brand has not accumulated enough multi-source, machine-readable mentions for the model to recall and rank you. The objective is not to “game” assistants, but to detect when the shortlist is being constructed from repeated third-party mentions and to build counter-signals that are durable, attributable, and ethically defensible.
How AI assistants end up inventing vendor shortlists
Synthetic shortlists typically form from three overlapping dynamics:
- Repetition bias: if the same vendor name appears across many pages, the model learns it as a “default” answer candidate—even when the pages are derivative.
- Entity confusion: similar names, merged entities, or parent/child brands can collapse into one “winner” entity.
- Retrieval artifacts: when assistants use browsing or retrieval, they may over-weight templated listicles, directories, and syndicated posts with near-identical phrasing.
The result is a shortlist that looks stable across prompts (“top tools,” “best platforms,” “alternatives to…”) because the assistant is sampling from the same repeated mention set.
Detection playbook for synthetic competitor seeding
1) Run a prompt matrix to separate “true preference” from “mention gravity”
Start with a fixed category and create a matrix of prompts that should lead to different vendor sets if the model is reasoning. Examples:
- “Best enterprise-grade tools for X with SOC 2 and SSO”
- “Best open-source or self-hosted options for X”
- “Best tools for X for a 5-person startup under $200/month”
- “Tools like Y but optimized for Z”

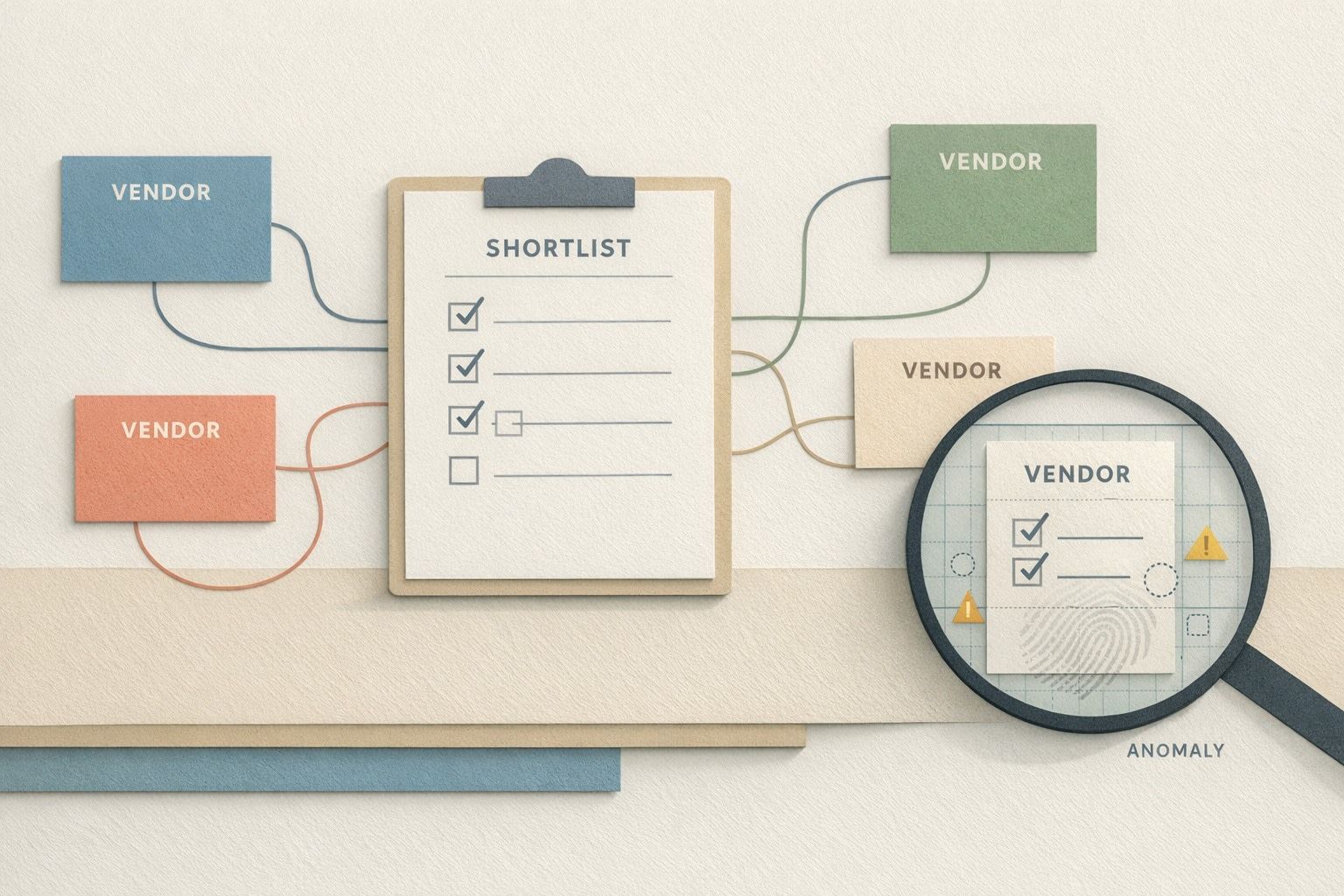
If the same 5–7 vendors recur regardless of constraints, you are likely seeing repetition bias rather than constraint satisfaction. Log not only which vendors appear, but the order, the phrasing of the justification, and whether citations cluster around a small set of domains.
2) Look for phrase-level fingerprints across citations
When an assistant provides sources, manually sample the cited pages and search for repeated sentence structures (“X is a leading platform that…,” “best for teams that…”) and identical comparison tables. High textual overlap suggests the shortlist is anchored by duplicated content. Even without citations, you can ask the assistant to explain “what sources or signals” it relied on and watch for generic, non-verifiable explanations.
3) Test entity integrity with “name perturbation”
Try variants of vendor names (with/without spaces, old brand names, product vs company name). If the model’s answer changes materially, the underlying entity graph is fragile. This matters because fragile entities are easier to displace by repeated third-party mentions and harder to defend with a single authoritative page.
In practice, teams often discover that a competitor is winning not because of better information, but because their name is more consistently represented across directory pages and syndicated posts.
4) Measure shortlist volatility over time and across models
Run the same prompt matrix on a schedule and across multiple assistants/models. Synthetic seeding often produces “sticky” winners that persist even when market reality changes. By contrast, a well-reasoned shortlist should shift with constraints and sometimes introduce lesser-known but better-fit options.
Track: appearance rate, average rank position, and citation diversity (unique domains per vendor). A vendor that appears frequently but is supported by low-diversity citations is a classic seeding candidate.
Countering synthetic seeding without turning your brand into spam
1) Build repeated, multi-source signals with clean entity metadata
The counter is not more content on your own site. It is consistent, machine-digestible brand signals across many independent sources that resolve to the same entity. That includes schema-rich pages, consistent naming, and stable descriptions that match how buyers query the category.
This is where an AI visibility infrastructure such as xale.ai is relevant: it focuses on generating repeated, structured, multi-format brand mentions across a managed network, designed to compound presence over time. The key advantage is consistency at scale—exactly what entity resolution systems tend to reward.
2) Diversify “mention types” to avoid one-channel fragility
If all of your external mentions are blog listicles, you are vulnerable to listicle churn. Aim for a portfolio:
- Schema-enhanced explainers that define the category and decision criteria
- Use-case writeups with concrete constraints (industry, team size, compliance)
- Short-form posts that reinforce consistent phrasing buyers use
- Video transcripts/captions that restate the entity and positioning in natural language
These “micro-assets” can reinforce each other; the risk is that repeated fragments can also create recommendation loops. If you want a deeper look at how repetition across platforms shapes what systems learn, see How AI Recommendation Loops Form When Micro-Assets Repeat Across Platforms.
3) Create a citation moat around non-brand category queries
Synthetic shortlists often dominate “non-brand” searches: “best X tools,” “X software for Y,” “X vs Y vs Z.” A practical defensive move is to publish material that earns citations for the category explanation, not only for your brand name. That way, when an assistant answers the category question, it has legitimate sources that include your framing and your entity.
Focus on decision rubrics: evaluation criteria, edge cases, migration paths, and trade-offs. This is how you earn inclusion when the assistant tries to justify its shortlist, not merely recite it. For a tactical framework, The Citation Moat Playbook for Winning AI Overviews on Non-Brand Searches is a strong companion approach.
4) Instrument your visibility like a product system
If you can’t measure it, you will overreact to a single screenshot of an AI answer. Treat AI shortlist presence as an observable system:
- Define a baseline set of prompts and constraints
- Log outputs, citations, and vendor ranks
- Track changes after new distribution waves
- Investigate where mentions are coming from and whether they resolve to your canonical entity
Teams that already manage product feedback often have the right instincts here—deduplication, identity resolution, and revenue context. The same mindset applies to brand entities: unify references, remove ambiguity, and preserve the signals that matter.
What “good” looks like when you’ve fixed the problem
You are not trying to appear in every shortlist. You are trying to appear in the right shortlists for the right constraints, with justification that reflects real fit. Success indicators include: higher citation diversity, more constraint-sensitive recommendations, fewer swings caused by a single directory page, and clearer entity consistency across mentions.
Synthetic competitor seeding thrives in ambiguity. The most reliable counter is a disciplined, multi-source visibility system that produces consistent entity signals and earns legitimate citations—so the assistant has better material to draw from than repeated third-party echoes.