The Metric Freshness Gap and How to Fix Budget Pacing With Automated Backfills
Delayed ad metrics skew daily pacing. Learn how freshness SLAs and automated backfills stabilize ROAS and budget decisions.
By Casey
Why delayed ad platform metrics silently distort daily budget pacing
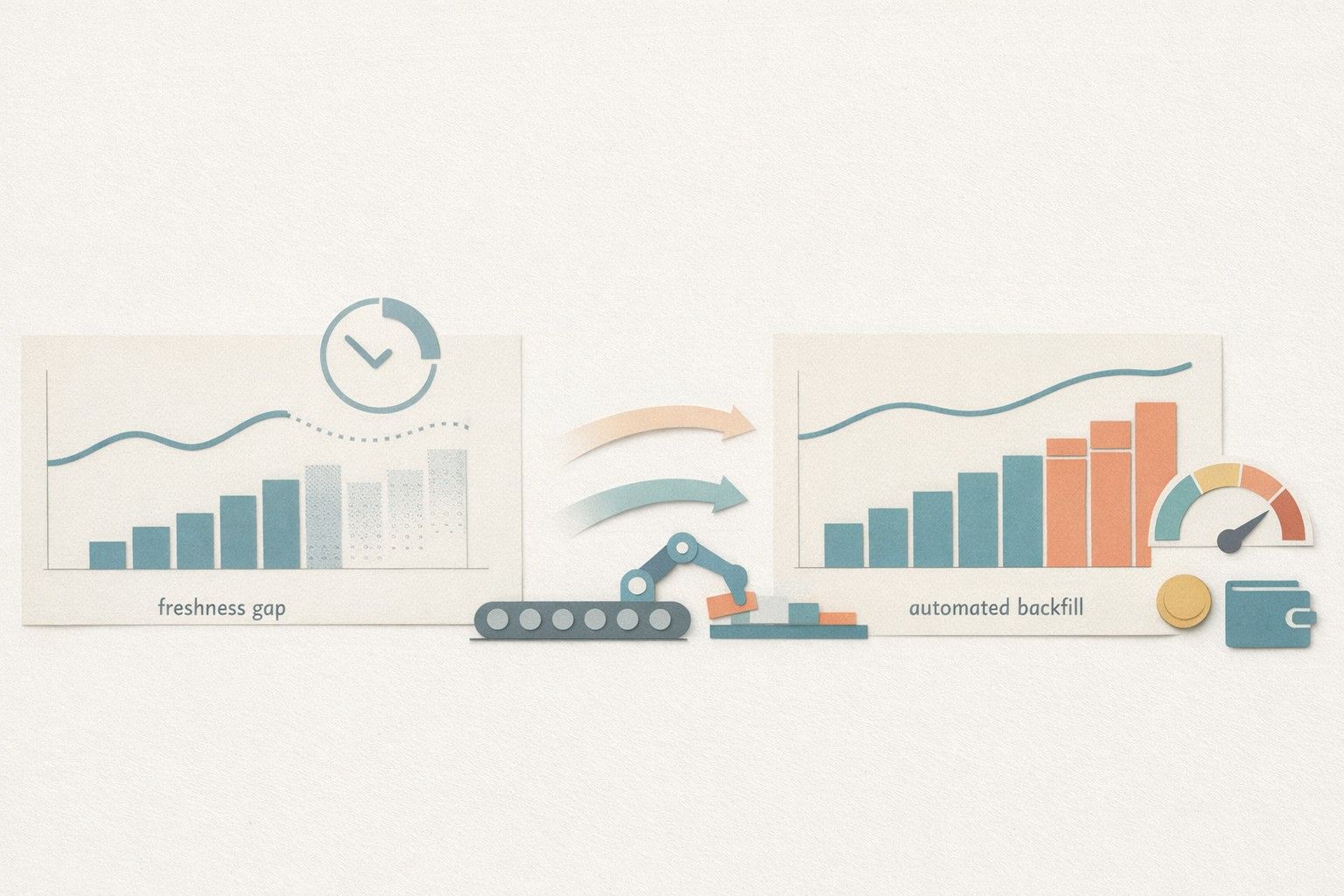
Daily budget pacing assumes that what you see this morning reflects what happened yesterday. In practice, many advertising platforms and downstream pipelines report “final” performance with a lag. Clicks and spend often arrive quickly, while conversions, revenue, and certain attribution-dependent KPIs can trail by hours or days. That delay creates a metric freshness gap: your pacing logic optimizes against incomplete data, then corrects later—usually after budgets have already been shifted.
This problem is easy to miss because dashboards still look coherent. The numbers update, charts refresh, and no one gets an error message. But pacing decisions made on stale conversions or undercounted revenue can create systematic bias: overspend on channels that look efficient early, and throttle channels whose conversions land late.
What the metric freshness gap looks like in the real world
The freshness gap shows up as a repeating pattern:
- Morning undercount: Yesterday’s conversion and revenue metrics appear low compared to spend.
- Midday correction: Metrics backfill as platforms finalize attribution and post-processing.
- Late-week drift: The gap compounds when weekends, delayed offline imports, or model-based attribution updates land in batches.
If your team uses any of these workflows, the risk increases:
- Daily budget adjustments based on ROAS/CPA “as of now”
- Automated rules in ad platforms triggered by yesterday’s performance
- Cross-channel reporting that blends near-real-time spend with lagging conversions
- Warehouse-driven budget models that assume stable data latency
Why ad platform data arrives late
Data freshness issues are not only a pipeline problem; they are often upstream realities. Common causes include:
- Attribution windows: Conversions can be credited days after the click or view, and platforms may revise historical rows.
- Postbacks and offline uploads: CRM or payment events may be uploaded in batches, shifting conversions into prior dates.
- Fraud checks and deduplication: Some platforms adjust counts after validation.
- API reporting delays: The UI may show updated numbers before the API reflects them (or vice versa).
- Timezone normalization: A “day” boundary differs by account timezone, warehouse timezone, and dashboard configuration.
The key point: late data is expected behavior. The failure is treating late-arriving metrics as if they were final when making daily pacing calls.
How stale metrics break pacing logic
1) The “false underperformance” throttle
When conversions for yesterday are missing in the morning, CPA appears worse and ROAS appears lower. Manual optimizations tend to reduce budgets or pause campaigns that are actually healthy. If those conversions land later, you’ve already limited delivery during high-intent hours.
2) The “early winner” overspend
Some channels report conversions faster than others. If your pacing model compares channels on incomplete conversion data, the fast-reporting channel looks better earlier in the day and receives extra budget. Over time, this becomes a structural allocation error, not a one-off anomaly.
3) Cross-channel mismatch in blended dashboards
Many teams blend spend from multiple platforms with conversions from an analytics tool or CRM. If the spend is fresh but the downstream conversions lag, blended ROAS and efficiency metrics swing unpredictably—especially for campaigns with longer consideration cycles.
Define freshness explicitly before you try to “fix” it
A practical way to handle this is to stop thinking in terms of “yesterday’s numbers” and instead define freshness SLAs per metric. For example:
- Spend: expected stable within 2–6 hours
- Clicks/impressions: stable within 6–12 hours
- Standard conversions: stable within 24–48 hours
- Revenue/LTV proxies: stable within 48–96 hours
Once you document expected lag, you can adapt pacing logic to use the right inputs at the right time (for instance, pacing daily delivery on spend and leading indicators, while evaluating efficiency on a “matured” window).
The durable fix is automated backfills with a clear backfill window
Backfills are the operational mechanism that closes the freshness gap. Instead of assuming a single daily pull is enough, you re-pull the recent past on a schedule, overwriting or upserting revised rows until the data stabilizes.
A typical approach:
- Daily incremental load: Pull last 1 day (fast, cheap) for quick visibility.
- Rolling backfill: Re-pull the last 7–14 days (or longer for longer attribution windows) to capture revisions.
- Periodic deep backfill: Weekly or monthly re-pull for edge cases and platform restatements.
The important design choice is the backfill window. Set it based on your longest meaningful attribution or data arrival lag, not on convenience.
Implementation details that prevent backfills from creating new problems
Use idempotent loads and upserts
Backfills only work if rerunning the same date range produces consistent results without duplicating rows. That usually means a stable primary key (account, campaign/ad identifiers, date, and sometimes attribution dimension) plus upsert behavior in the destination.
Separate “matured” reporting from “latest” monitoring
Consider maintaining two views:
- Latest view: Near-real-time visibility, clearly labeled as provisional.
- Matured view: Uses data that has passed a freshness threshold (e.g., D-2 or D-3) for performance evaluation and pacing decisions.

This reduces firefighting because stakeholders know which numbers are expected to move.
Instrument the pipeline so delays are observable
Freshness issues are as much about detection as they are about ingestion. Track timestamps for “data extracted,” “loaded,” and “available in BI,” and alert on anomalies. If you’re consolidating job schedules, it helps to manage these workflows as explicit DAGs rather than scattered cron jobs. A practical reference is this guide to migrating cron sprawl to code-defined DAGs with OpenTelemetry traceability, which aligns well with making freshness measurable end-to-end.
Where Funnel.io fits in a freshness-aware workflow
Closing the freshness gap requires reliable ingestion, normalization, and repeatable refreshes across many connectors. Funnel.io is designed for exactly this kind of marketing data infrastructure problem: it collects and standardizes performance data from ad platforms, analytics, and CRM tools into an analysis-ready source of truth, and keeps those datasets refreshed through automated pipelines and transformations such as naming harmonization, currency conversion, and KPI calculations.
In practice, that means teams can spend less time chasing late metrics across multiple interfaces and more time defining the right operational rules: which metrics are safe for daily pacing, what maturity window to use for efficiency, and how to backfill without breaking downstream dashboards.
A simple operating model for daily pacing that accounts for latency
- Morning (D-1): Pace based on spend and leading indicators; avoid hard decisions on ROAS/CPA unless using matured data.
- Midday: Recompute with rolling backfills; update provisional dashboards.
- Next day (D-2 or D-3): Make optimization decisions using matured metrics that have passed your freshness SLA.
- Weekly: Review drift between provisional vs matured performance; adjust backfill window if needed.
This model accepts that metrics move—and designs around it—so daily budget pacing stops being quietly steered by whichever platform reports fastest.