Backfill-Safe Scheduler Pattern for Idempotent Internal Jobs
A practical pattern for replayable internal jobs using run IDs, lease locks, DLQs, and end-to-end backfill safety.
By Casey
Why “backfill-safe” scheduling matters for internal systems
Most internal schedulers work fine until you need to replay history. The moment you backfill a week of analytics, rebuild cached artifacts, re-run billing exports, or recompute a metric after a logic change, “cron-like” assumptions break: jobs overlap, duplicate side effects, contend for shared resources, and silently skip work due to time-based heuristics.
A backfill-safe scheduler pattern treats every run as a deterministic, replayable unit of work. It assumes the future includes reruns, partial failures, worker restarts, and multiple concurrent executors. The goal is not simply “run on time”, but “run exactly once in effect” even when executed at least once.
The pattern at a glance
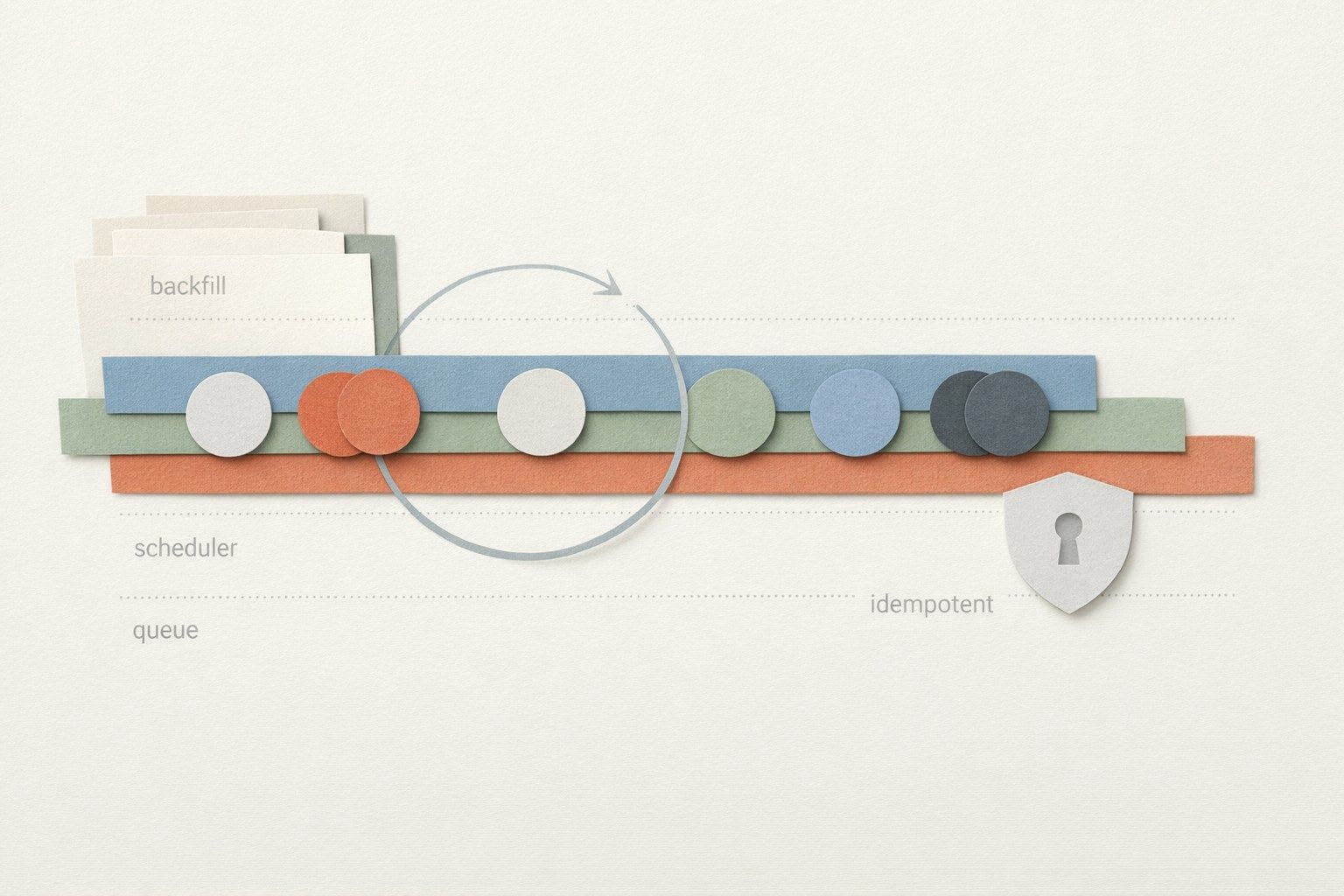
The backfill-safe scheduler pattern is built from four concrete primitives:
- Run identity: every job execution has a stable idempotency key derived from input parameters (time window, tenant, version).
- Lease locks: a short-lived lock prevents concurrent processors from claiming the same unit of work.
- Dead-letter queue (DLQ): failures are persisted with context and retry policy, not lost in logs.
- End-to-end run replay: any run can be reconstructed from stored inputs, checkpoints, and outputs.
1) Define a stable run identity
Backfills become safe when you can answer, for any execution: “Is this the same run as before?” A run identity is usually a hashable tuple such as:
- Job name (e.g., recompute_daily_revenue)
- Tenant or workspace identifier
- Window start/end (or a logical partition key like 2026-04-20)
- Code version or semantic “logic version”
This key should be stable across retried attempts, but change when the meaning of the job changes. In practice, teams often keep both a run_id (stable) and an attempt_id (unique per retry). The stable run_id drives idempotency and deduplication; the attempt_id drives observability.
Idempotency targets should be explicit
“Idempotent job” is not a property of the scheduler; it’s a property of the job’s side effects. Make the target explicit:
- Database writes: use UPSERTs keyed by (tenant, partition) and write in one transaction where possible.
- Object storage: write to a run-scoped path, then atomically promote (rename/copy) if your storage semantics allow it.
- External APIs: pass an idempotency key if supported, or store a local “sent” record keyed by run_id.
2) Use lease locks to prevent concurrent claims
Lease locks are time-bound locks that must be renewed. They solve the “two workers picked the same task” problem without requiring perfect worker shutdown behavior. The core rules:
- Acquire the lease for a run_id before executing.
- Renew the lease periodically while executing.
- Release the lease on success (or let it expire on crash).

Implementations commonly live in PostgreSQL (row-level lease with expires_at), Redis (SET NX + TTL), or a dedicated lock service. PostgreSQL is often sufficient for internal platforms because it also stores run state and attempt history, enabling consistent transitions.
Lease duration is a design decision
If the lease is too short, long jobs will lose the lock and be duplicated. If it’s too long, crashed workers delay recovery. A pragmatic approach is: short lease (e.g., 60–120 seconds) plus renewals, and a heartbeat that updates progress. When a lease is stolen (renewal fails), the job must stop safely or switch to read-only mode.
3) Persist run state transitions in a run ledger
To be replayable, a system needs a durable run ledger. At minimum, store:
- run_id, attempt_id
- inputs (time window, tenant, parameters, logic version)
- state transitions: QUEUED → RUNNING → SUCCEEDED/FAILED
- timestamps, worker identity, and last heartbeat
- output pointers (tables updated, files written, artifact IDs)
This ledger is what allows you to backfill confidently, audit what happened, and diagnose partial failures. It also enables “skip if already succeeded” behavior that is correct even across restarts.
4) Route failures into a dead-letter queue with policy
Retries without a DLQ are a recipe for silent loops or manual archaeology. A DLQ record should capture:
- the run_id and attempt_id
- the failure category (transient, permanent, unknown)
- error message + stack trace (bounded)
- the last successful checkpoint (if any)
- retry policy decisions (next run time, max attempts, backoff)
Critically, DLQ processing should be first-class: searchable, alertable, and replayable. That replay should create a new attempt for the same run_id, not a new run with a new identity, unless you are changing parameters or logic version.
5) Make end-to-end replay a product feature, not a rescue plan
“Replay” means more than requeueing. It means you can reproduce the full execution path for a run: the inputs, the code version, the intermediate checkpoints, and the outputs. Two tactics make this realistic:
- Checkpoints: store progress markers such as “partition X completed” or “cursor advanced to Y”.
- Deterministic input snapshots: when the job depends on mutable upstream data (e.g., a list of accounts), snapshot that list per run.
With this in place, backfills stop being scary. You can re-run a day, a month, or an entire tenant with predictable behavior, and you can compare outputs between logic versions.
How this fits into modern DAG-based internal platforms
Many teams start with cron sprawl, then migrate to code-defined DAGs to manage dependencies, retries, and observability. This pattern complements that direction: DAG orchestration decides what should run and when, while backfill-safe primitives guarantee that each node’s side effects remain correct under replay. If you are already consolidating schedulers, the approach aligns naturally with migrating cron sprawl to code-defined DAGs with traceability.
Platforms like windmill.dev are designed around real code execution with workflow DAGs, operational visibility, and low overhead. The practical advantage for this pattern is that you can implement run_id generation, lease acquisition, and DLQ routing in normal code (Python/TypeScript/SQL, etc.), while keeping run metadata and logs tied to each attempt. That makes replay and auditing an everyday capability rather than an ad-hoc script collection.
Implementation checklist for a backfill-safe scheduler
- Define run_id = hash(job, tenant, partition/window, logic_version)
- Store a run ledger table with state transitions and outputs
- Acquire a lease lock before execution; renew heartbeat during execution
- Write idempotent side effects (UPSERTs, run-scoped artifacts, idempotency keys)
- Record checkpoints for long runs and partitioned work
- On failure, persist a DLQ entry with retry/backoff policy
- Support replay: same run_id, new attempt_id, same inputs, optional logic_version bump
Common failure modes this pattern prevents
- Duplicate sends during backfills (emails, webhooks, API writes)
- Overlapping recomputes that fight over the same partitions
- “Successful” jobs with partial output that only show up weeks later
- Retry storms with no visibility into why runs keep failing
- Irreproducible incidents because inputs and code versions weren’t captured
Where to start when your current system is cron-based
You don’t need to rewrite everything. Pick one high-impact backfill scenario (a metric recompute, a daily export, or a cache rebuild). Add run identity and a ledger first, then introduce lease locks, then DLQ + replay. This incremental approach also pairs well with improving metric backfills and freshness, especially when budget pacing or reporting depends on reliable recomputation windows.