Preventing LLM Cache Poisoning in Edge-Cached AI APIs
Practical patterns to stop LLM cache poisoning at the edge with safer cache keys, isolation, and observability.
By Casey
Why cache poisoning is now an LLM reliability and security problem
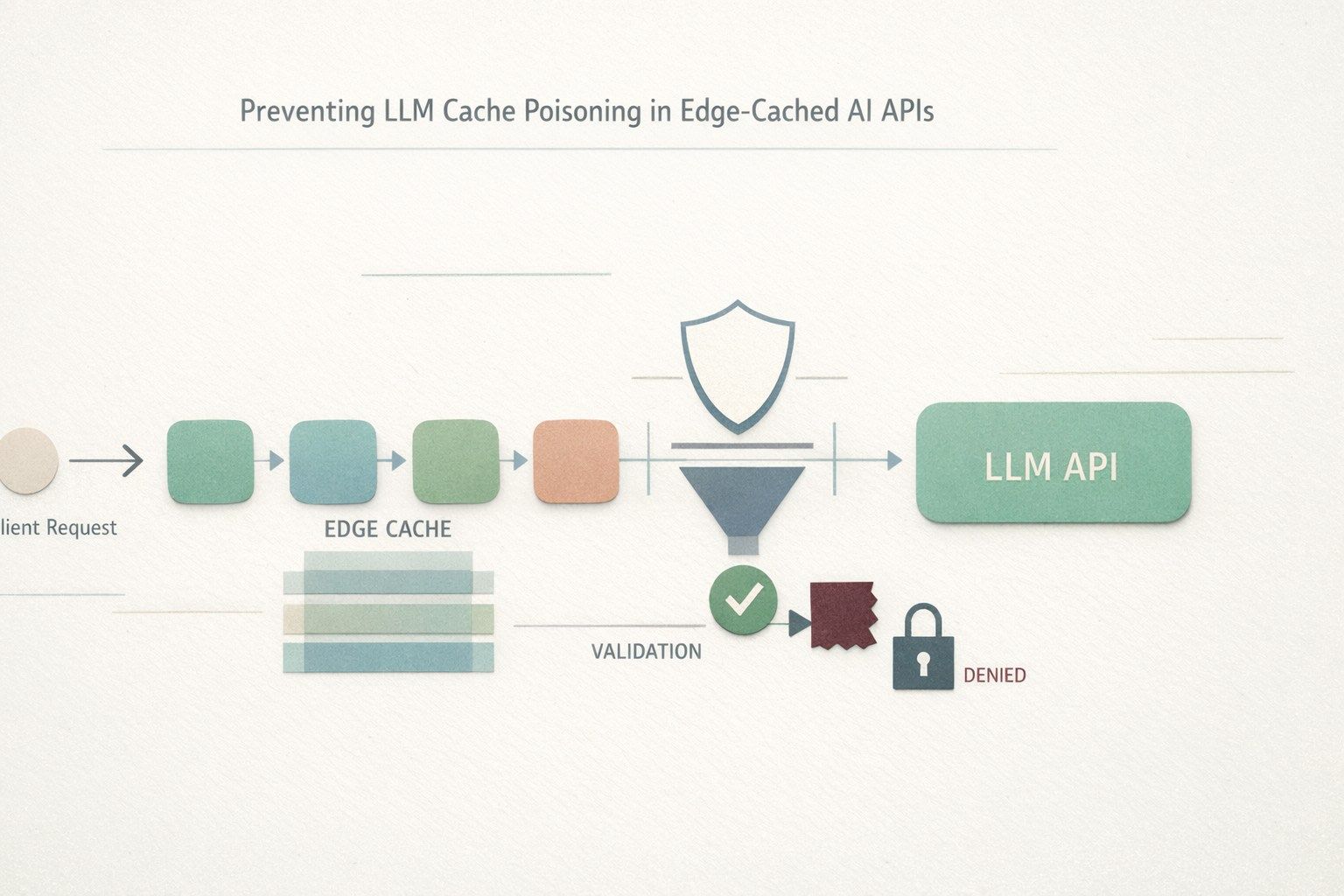
Edge caching is no longer limited to static assets. Many AI APIs cache prompt templates, retrieval results, tool outputs, embeddings, moderation decisions, and even full model responses to reduce latency and cost. When those layers sit behind a CDN or edge runtime, the blast radius of a single bad cache entry can expand from one user to thousands of users in minutes.
LLM cache poisoning happens when an attacker (or an accidental misconfiguration) causes untrusted content to be stored under a cache key that later serves different users. Prompt/response contamination
This article focuses on prevention techniques that apply to edge-cached AI APIs, with practical patterns you can implement in CDNs and edge compute platforms such as cloudflare.com.
Threat model and common failure modes
Cache poisoning and contamination rarely come from a single vulnerability; they come from composing caching with highly variable inputs. The most common failure modes are predictable:
- Over-broad cache keys that ignore user identity, tenant, auth scope, locale, or model version.
- Caching personalized outputs (responses that depend on user data, conversation history, or entitlements) as if they were public.
- Header and query normalization mistakes where the edge considers two requests “equivalent” but the origin/model does not.
- Tool output caching without provenance (e.g., caching a web fetch or CRM lookup result that was performed under a different user’s permissions).
- Streaming and partial response caching bugs that store incomplete tokens or error pages and replay them as valid completions.
- Prompt template caching with untrusted interpolation where attacker-controlled fields are stored in the cached template rather than in request-scoped variables.
Design cache boundaries before you design cache keys
Before getting into hashing strategies, decide what must never be shared. In most AI products, these items should be treated as strictly private and either not cached or cached only per-user/per-tenant:
- Any response that includes user-specific data, account metadata, or policy decisions.
- Conversation memory summaries and tool traces that include identifiers.
- RAG context that is derived from private indexes or ACL-protected documents.
- System prompts that embed customer secrets (API keys, internal URLs, proprietary instructions).

Public caching can be appropriate for truly public outputs (e.g., a documentation assistant answering a general question from a public corpus) but even then the cache key must include model and prompt-template versioning to prevent cross-version contamination.
Cache key construction for LLM workloads
1) Make cache keys explicit and deterministic
Relying on default CDN caching behavior is risky for AI endpoints. Construct an explicit cache key that is deterministic and auditable. A robust LLM cache key typically includes:
- Tenant identifier (or “public” if truly public).
- User identifier or auth scope hash if responses depend on entitlements.
- Model ID and model parameters that change output (temperature, top_p, max_tokens, safety settings).
- Prompt template version and a hash of the normalized prompt payload.
- Toolchain version if you call tools (search, DB, CRM) whose logic changes independently.
- Locale/timezone when your assistant localizes output or date formatting.
The key idea: if two requests can legitimately produce different answers, they must not share a cache key.
2) Normalize inputs before hashing
Attackers love “almost identical” requests that bypass key equality. Normalize your cacheable request representation:
- Canonical JSON serialization (stable key ordering, consistent whitespace rules).
- Drop non-semantic fields (client timestamps, request IDs) from the hash input.
- Include only headers you intentionally vary on; ignore the rest.
If you do RAG, include a hash of the retrieved document IDs + their versions, not the raw text. That prevents subtle prompt injection stored in cached context blobs and makes cache invalidation predictable.
3) Separate “prompt caching” from “response caching”
A common mistake is caching the full response keyed only by the prompt text. In production systems, the response is a function of more than the prompt: policies, user scopes, tool outputs, and model version all matter. Consider a two-layer approach:
- Prompt/template cache for static system instructions and compiled templates (safe if templates do not embed user data).
- Response cache only for public or strictly scoped outputs, with explicit vary dimensions.
Cache-control rules that prevent accidental sharing
Use conservative defaults at the edge:
- Default to no-store for authenticated requests, then allowlist specific endpoints or scopes that are safe to cache.
- Honor origin cache headers only if your origin is already opinionated and correct; otherwise override at the edge.
- Short TTLs for AI responses unless the content is clearly immutable and public.
- Stale-while-revalidate with safeguards: revalidate per key, and ensure revalidation uses the same auth scope and parameters.
Edge platforms that combine caching with serverless compute make it practical to enforce these rules close to users, where the caching actually happens.
Preventing prompt/response contamination in multi-tenant agent systems
Agentic APIs add additional contamination vectors because they chain steps. Three patterns reduce cross-request bleed-through:
- Step-scoped caches: cache tool results separately per step and per permission scope, not under a global “agent result” key.
- Signed provenance: attach a signature to cached tool outputs that includes tenant, scope, and tool version; reject mismatches on read.
- Conversation boundary enforcement: memory and summaries should be stored in user/tenant isolated storage and never in shared edge caches.
If you are deploying agents at the edge, the operational patterns described in Deploying AI Agents at Scale With Cloudflare Agent Cloud map naturally to these isolation and provenance requirements.
Observability and detection at the edge
Prevention is strongest when you can prove what happened. Log (without leaking sensitive data) the cache decisions your edge makes:
- Cache key components (hashed or tokenized), TTL, hit/miss, and revalidation outcome.
- The “vary dimensions” chosen for the request (tenant, scope, model version, template version).
- Tool call identifiers and whether tool outputs were served from cache.
When combined with traces, you can detect anomalies such as cache hits across different tenants or scopes. For teams standardizing their pipelines, an approach like Migrating Cron Sprawl to Code-Defined DAGs With OpenTelemetry Traceability is a useful reference for making those traces consistent across scheduled and realtime workloads.
Hardening checklist for edge-cached AI APIs
- Explicit cache key that includes tenant, auth scope, model + parameters, and template/tool versions.
- Never cache personalized responses publicly; treat authenticated traffic as no-store by default.
- Normalize request bodies and allowlist headers that influence caching.
- Cache RAG by document IDs/versions rather than raw retrieved text.
- Protect tool caches with provenance (scope- and version-bound signatures).
- Instrument cache decisions so cross-tenant or cross-scope hits are detectable.